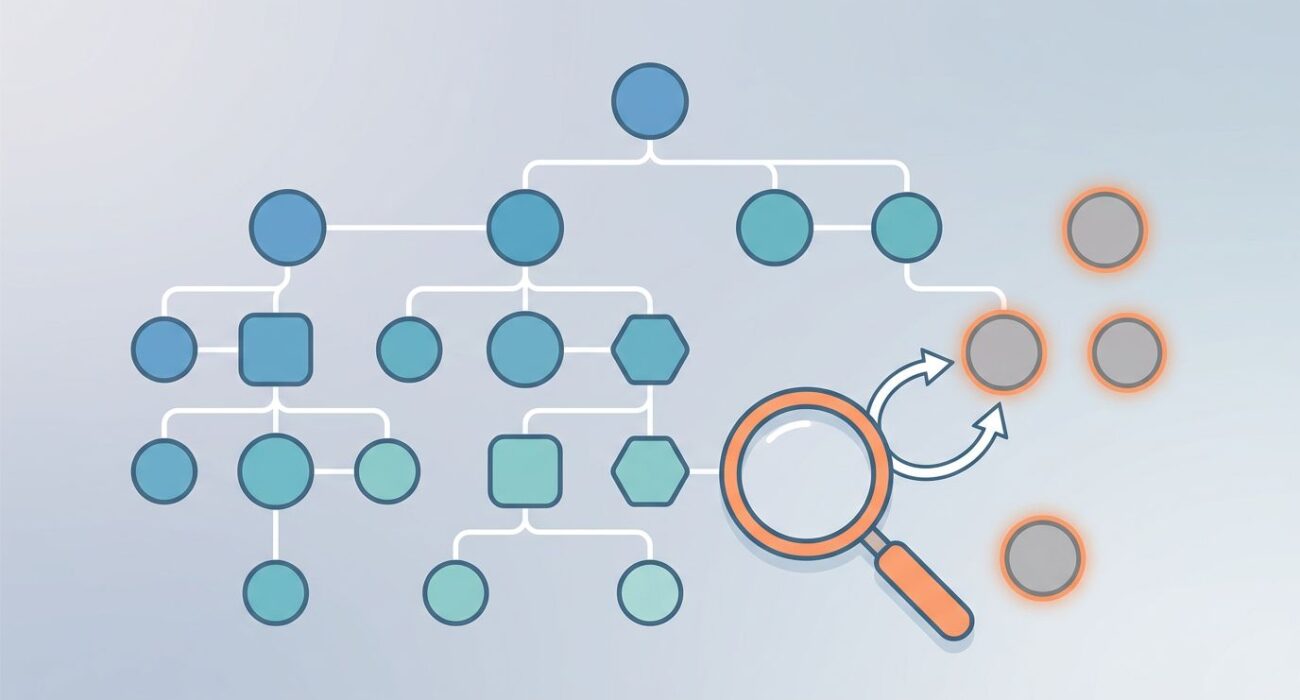
Sitenizde indekslenen ama hiçbir yerden ulaşılmayan sayfalar varsa, sessizce trafik ve otorite kaybediyorsunuz. SEO araçlarında “orphan pages” diye görülen bu URL’ler, çoğu zaman sitemap’te durur ama site mimarisinde gerçek bir yeri olmaz.
Sorun yalnızca tarama bütçesiyle sınırlı değil. Kullanıcı bu sayfalara denk gelmez, arama motoru sayfanın önemini düşük görür ve içerik ekibi zamanla bu URL’leri unutmaya başlar. Kalıcı çözüm, doğru tespit ve planlı iç link çalışmasıyla gelir.
Yetim sayfalar neden fark edilmez ve neden sorun çıkarır?
Orphan page, en basit haliyle, site içinde hiçbir iç link almayan sayfadır. Yani URL vardır, bazen indekslenmiştir, hatta trafik bile alabilir; ancak menüden, kategori sayfasından, ilgili yazılardan veya başka bir içerikten bu sayfaya yol gitmez.
Bu durum genelde site yenilemesi, kategori değişimi, eski kampanya sayfaları, taşınan blog içerikleri ve unutulan landing page’lerde ortaya çıkar. Bir ekip yeni tasarım yayınlar, eski bağlantılar düşer, sitemap güncel kalır ve problem aylarca görünmez.
Asıl sorun şudur, arama motorları bir sayfanın önemini yalnızca var olmasına bakarak anlamaz. İç link almayan URL, site içi otorite akışından kopar. Üstelik kullanıcı akışına girmediği için dönüşüm üretmesi de zorlaşır.
Sitemap’te görünen bir URL, site içinde link alıyor demek değildir.
Yine de her orphan page hata değildir. Teşekkür sayfaları, ödeme sonrası ekranlar, bazı test URL’leri veya geçici kampanya sayfaları bilerek izole bırakılabilir. Bu yüzden önce “tespit”, sonra “temizlik”, en son “çözüm” gerekir. Düzenli teknik kontrol yapan ekipler bu boşlukları daha erken yakalar; bu da profesyonel SEO danışmanlığı süreçlerinde en sık görülen kazanımlardan biridir.
Orphan sayfaları tespit etmenin en pratik yolu
En iyi yöntem, bir crawler çıktısını farklı URL kaynaklarıyla karşılaştırmaktır. Tek başına site taraması yetmez; çünkü iç link almayan sayfa zaten tarama sırasında görünmeyebilir. Bu yüzden “sitede bildiğim URL’ler” ile “crawl’da gördüğüm URL’ler” arasındaki farkı bulmanız gerekir.
Araçtan bağımsız temel mantık
Aşağıdaki mantık, araç değişse de aynıdır.
- Önce canlı bir site taraması alın. Screaming Frog, Sitebulb, Ahrefs Site Audit, Semrush Site Audit veya benzeri bir crawler iş görür. Buradaki amaç, iç linklerle gerçekten keşfedilen URL listesini çıkarmaktır.
- Sonra XML sitemap’teki URL’leri dışa aktarın. Sitemap’te olup crawl’da görünmeyen sayfalar, ilk orphan adaylarıdır.
- Ardından Google Search Console’dan indekslenen veya gösterim alan sayfaları alın. Çünkü bazı orphan sayfalar sitemap’te olmayabilir ama Google onları tanıyor olabilir.
- Mümkünse analytics verisini ekleyin. Organik, reklam veya e-posta trafiği almış açılış sayfaları, taramada görünmese bile iş açısından değerli olabilir.
- En sonda tüm listeleri normalize edin. HTTP ve HTTPS farkı, sondaki slash, büyük-küçük harf, parametreli URL’ler ve canonical farklılıkları temizlenmeden doğru sonuca ulaşamazsınız.
Bu karşılaştırma mantığı, markadan bağımsız en sağlam yoldur. Çünkü araç raporları, beslendikleri veri kadar doğrudur. Tek crawl raporuna bakıp “sitede orphan yok” demek güvenli bir çıkarım değildir.
Araçlarla kontrolü hızlandırın
Screaming Frog, sitemap, Search Console ve analytics kaynaklarını bir araya getirince güçlü bir kontrol sunar. Sitebulb, kaynak bazlı URL farklarını görselleştirmede işinizi hızlandırır. Ahrefs ve Semrush da site denetimi tarafında benzer boşlukları gösterebilir; ancak sonuçların kalitesi, bağladığınız kaynaklara bağlıdır.
Burada kritik nokta şudur, araç ne söylerse söylesin son karar sizin filtrelerinizle verilir. Çünkü yanlış pozitifler çok çıkar. Örneğin:
- Noindex bir test sayfası gerçekten sorun olmayabilir.
- Canonical’ı başka URL’ye giden sayfa ana aday olmayabilir.
- 301 yönlendiren eski sayfa, orphan değil teknik borç olabilir.
- Parametreli URL’ler raporu kirletebilir.
Kısa bir kontrol kuralı kullanın: URL 200 durum kodu veriyor mu, indekslenmesini istiyor musunuz, canonical kendine mi dönüyor, iş hedefi var mı, site içinde kullanıcıya mantıklı bir yolu var mı? Bu beş sorudan ikisine bile “hayır” diyorsanız, o sayfa iç link çözümünden önce ayrı değerlendirilmelidir.
İç link çözümünü kurarken rastgele davranmayın
Yetim sayfayı bulmak işin yarısıdır. Asıl farkı, doğru kaynaktan verilen doğal iç link oluşturur. Çünkü alakasız bir sayfadan eklenen tek bir bağlantı, teknik olarak sorunu kapatır gibi görünse de gerçek performans getirmez.
Doğru kaynak sayfayı seçin
İlk kural, konu yakınlığıdır. İç link vereceğiniz kaynak sayfa, hedef URL ile aynı arama niyetine veya aynı içerik kümesine yakın olmalıdır. Blogdaki “teknik SEO kontrol listesi” yazısından, “site mimarisi” rehberine link vermek doğaldır. Ancak ilgisiz bir kampanya sayfasından aynı linki vermek zayıf kalır.
İkinci kural, görünürlüktür. Link kaynağı kendi başına taranan, indekslenen ve trafik alan bir sayfa olmalıdır. Zaten derinde kalan zayıf bir URL’den link vermek, orphan sayfayı tam olarak kurtarmaz.
Aşağıdaki tablo, kaynak sayfa seçimini hızlandırır:
| Kaynak sayfa tipi | Ne zaman iyi seçimdir | Dikkat edilmesi gereken risk |
|---|---|---|
| Kategori veya hub sayfası | Konu kümesini topluyorsa | İnce içerikse etkisi sınırlı kalır |
| Trafik alan evergreen içerik | Hedef sayfa aynı niyete yakınsa | Zoraki anchor metin sırıtır |
| İlgili eski blog yazısı | Güncelleme yapılabiliyorsa | Sayfa çok derindeyse katkı düşer |
| Menü veya sabit bloklar | Gerçekten kalıcı navigasyon gerekiyorsa | Site geneline yayılmış aşırı link oluşabilir |
Genel kural basittir, önce hub veya kategori seviyesinde görünür bir bağlantı verin, sonra 1 veya 2 ilgili içerikten destek ekleyin. Çoğu durumda 2 ila 5 iyi kaynak, onlarca zayıf linkten daha iyidir.
Crawl depth, öncelik ve anchor metin dengesi
Crawl depth, yani bir sayfanın ana sayfadan kaç tık uzakta olduğu, orphan çözümünde doğrudan önemlidir. Hedefiniz, değerli yetim sayfaları 2 ila 4 tık içinde erişilebilir hale getirmektir. Çünkü hem kullanıcı hem bot, yüzeyde duran sayfaları daha hızlı bulur.
Önceliği şu sırayla verin: gelir getiren sayfalar, gösterim alan ama link almayan sayfalar, kaliteli backlink’i olan eski URL’ler, güncel ve yeniden kullanılabilir içerikler. Buna karşılık eski kampanya sayfaları, zayıf filtre URL’leri ve artık iş değeri taşımayan içerikler sona kalabilir.
Anchor metin tarafında da ölçülü olun. Her linkte tam eşleşen anahtar ifadeyi kullanmak doğal durmaz. Bunun yerine konuya uygun, akışa oturan ifadeler seçin. “Teknik SEO denetimi”, “site mimarisi rehberi” veya “ürün karşılaştırma sayfası” gibi doğal bağlantılar daha sağlıklıdır.
Bir örnek düşünün. E-ticaret blogunuzda “koşu ayakkabısı numara seçimi” rehberi indeksli ama hiçbir yerden link almıyor olsun. Bu sayfayı yalnızca footer’a atmak yerine, ilgili kategori sayfasına, “koşu ayakkabısı nasıl seçilir” yazısına ve ürün karşılaştırma içeriğine bağlamak daha iyi sonuç verir. Böylece URL, gerçek bir kullanıcı yoluna girer.
Ayrıca aşırı optimizasyondan kaçının. Her paragrafta link yığmak, site geneli sabit bloklara alakasız bağlantılar eklemek ve sırf orphan raporunu temizlemek için metni bozmak, kısa vadede raporu düzeltir ama uzun vadede kaliteyi düşürür.
Kısa uygulama planı ve örnek senaryo
İlk listeyi çıkarmak için uzun bir projeye ihtiyacınız yok. Yarım saatlik disiplinli bir çalışma, çoğu sitede ana problemi gösterir.
Küçük bir kontrol listesiyle başlayın:
- Crawl çıktısını alın ve yalnızca 200 kodlu indekslenebilir sayfaları bırakın.
- XML sitemap URL’lerini aynı formatta dışa aktarın.
- Search Console’dan gösterim alan sayfaları çekin.
- Listeleri tek sütunda birleştirip eşleşmeyen URL’leri bulun.
- Bilerek izole bırakılan sayfaları ayıklayın.
- Kalan adayları iş değeri ve konu yakınlığına göre puanlayın.
Pratik bir senaryo verelim. Blog yapısı yenilenen bir B2B sitede eski rehberler sitemap’te kalıyor, ancak kategori bağlantıları yeni yapıda kaldırılıyor. Sonuçta 35 rehber URL indeksli kalıyor ama içerik akışından kopuyor. Çözüm, bu URL’leri topluca menüye eklemek değil. Önce ana konu sayfaları oluşturulur, sonra en güçlü 10 içerikten bağlamsal linkler verilir, en sonda da ilgili kategori blokları güncellenir. Bu yaklaşım, daha geniş bir etkili SEO stratejisi oluşturma planıyla birleşince kalıcı hale gelir.
Düzenli bakım da şarttır. Her ay “sitemap’te var, crawl’da yok” raporu çıkarın. Büyük tasarım değişimlerinden, kategori taşımalardan ve içerik temizliği sonrası güncellemelerden hemen sonra bu kontrolü tekrarlayın.
Sonuç
Orphan pages sorunu, çoğu zaman içerik eksikliğinden değil, zayıf site içi bağlantı disiplininden doğar. Doğru yöntem, URL’leri farklı kaynaklardan karşılaştırmak ve sonra her değerli sayfayı mantıklı bir iç link yoluna yerleştirmektir.
En güçlü farkı, doğru kaynak sayfa seçimi yaratır. Eğer bir URL kullanıcı akışına, konu kümesine ve makul crawl depth içine giriyorsa, artık yalnızca indekslenen bir sayfa değil, çalışan bir sayfa haline gelir.