
Sayfa tarayıcıda dolu görünüyor olabilir, ama Googlebot kullanıcıdan farklı olarak bazen yalnızca boş bir kabuk görür. Teknik SEO stratejisinin önemli bir parçası olan JavaScript SEO testi tam da bu farkı yakalamak için yapılır.
JavaScript ile kurulan sitelerde sorun çoğu zaman “indekslenmedi” noktasında değil, “doğru render edilmedi” noktasında başlar. Bu yüzden ilk HTML yanıtı, render edilmiş DOM, ağ istekleri ve head etiketleri birlikte okunmalıdır.
Aşağıdaki yöntemler, sorunun nerede çıktığını bulmanıza ve gördüğünüz bulguyu doğru yorumlamanıza yardım eder.
Ana Çıkarımlar
- Kritik SEO sinyalleri (başlık, H1, ana metin, canonical, internal links) initial HTML yanıtında yer almalı; client-side rendering’e bağımlılık indeksleme riskini artırır.
- Initial HTML ile rendered DOM’u karşılaştırın, DevTools Network/Console’da API hataları, hydration mismatch ve robots engellerini tespit edin.
- Googlebot’un render süreci gecikmeli olduğundan, lazy-load, geç eklenen head etiketleri ve render sonrası linkler crawlability’yi bozar.
- Teşhis akışı: Kaynak HTML > Rendered DOM > GSC Canlı URL Testi > Ağ/Konsol inceleme; farklar kök nedeni gösterir.
- Çözüm: SSR, SSG veya ISR ile kritik içeriği sunucu tarafında üretin, dynamic rendering’i kısa vadeli köprü olarak kullanın.
Render sorunu neden gözden kaçar
Mayıs 2026 itibarıyla Google’ın render katmanı evergreen Chromium temelli çalışıyor. Yani modern JavaScript’i eskisine göre çok daha iyi işliyor. Buna rağmen sorun bitmiyor, çünkü render hâlâ client-side rendering ile ikinci aşamada gerçekleşiyor. İlk istek sırasında gelen HTML zayıfsa, indekslemenin iki dalgası nedeniyle sayfanın anlamı ertelenmiş olur.
Bu gecikme küçük görünür, ama etkisi büyüktür. Başlık, ürün metni, dahili linkler ya da canonical yalnızca istemci tarafında ekleniyorsa, Googlebot indeksleme sırasında her zaman aynı sonucu görmeyebilir. Bazı URL’lerde client-side rendering hızlı olur, bazılarında kuyruk, hata ya da eksik istek devreye girer; bu durum sayfa hızını da olumsuz etkiler.
Bu yüzden “kullanıcı sayfayı görüyor” cümlesi teşhis için yetmez. Tarayıcı, önbellek, önceki oturum ve etkileşimler sayesinde eksik şeyi telafi edebilir. Bot ise daha sade bir yol izler. İlk HTML, kritik kaynaklar ve başarılı veri çağrıları yoksa sayfanın ana gövdesi geç gelir ya da hiç gelmez.
JavaScript odaklı SEO testinde ilk amaç puan toplamak değildir. Amaç, Googlebot’un indeksleme nihai hedefi olan şu farkı net görmekten ibarettir: sunucunun döndürdüğü belge ile tarayıcının sonradan kurduğu belge aynı şeyi mi söylüyor? Eğer yanıt hayırsa, sonraki iş o farkın sebebini bulmaktır.
En sık rastlanan belirtiler bellidir: boş kalan içerik alanları, geç yüklenen H1 ve metin blokları, görünmeyen görseller, render sonrası oluşan linkler, API hataları, hydration mismatch uyarıları ve 200 dönen ama fiilen “bulunamadı” davranan sayfalar.
JavaScript SEO testi için güvenilir akış
Site audit sürecinin temel bir bileşeni olan sağlam bir test, tek araca bakarak yapılmaz. Aynı URL’yi birkaç açıdan görmeniz gerekir. Ön tarama için teknik sorunları görmek üzere SEO analizi aracı işinizi hızlandırır, ama derin teşhis için aşağıdaki akışı izlemek gerekir.
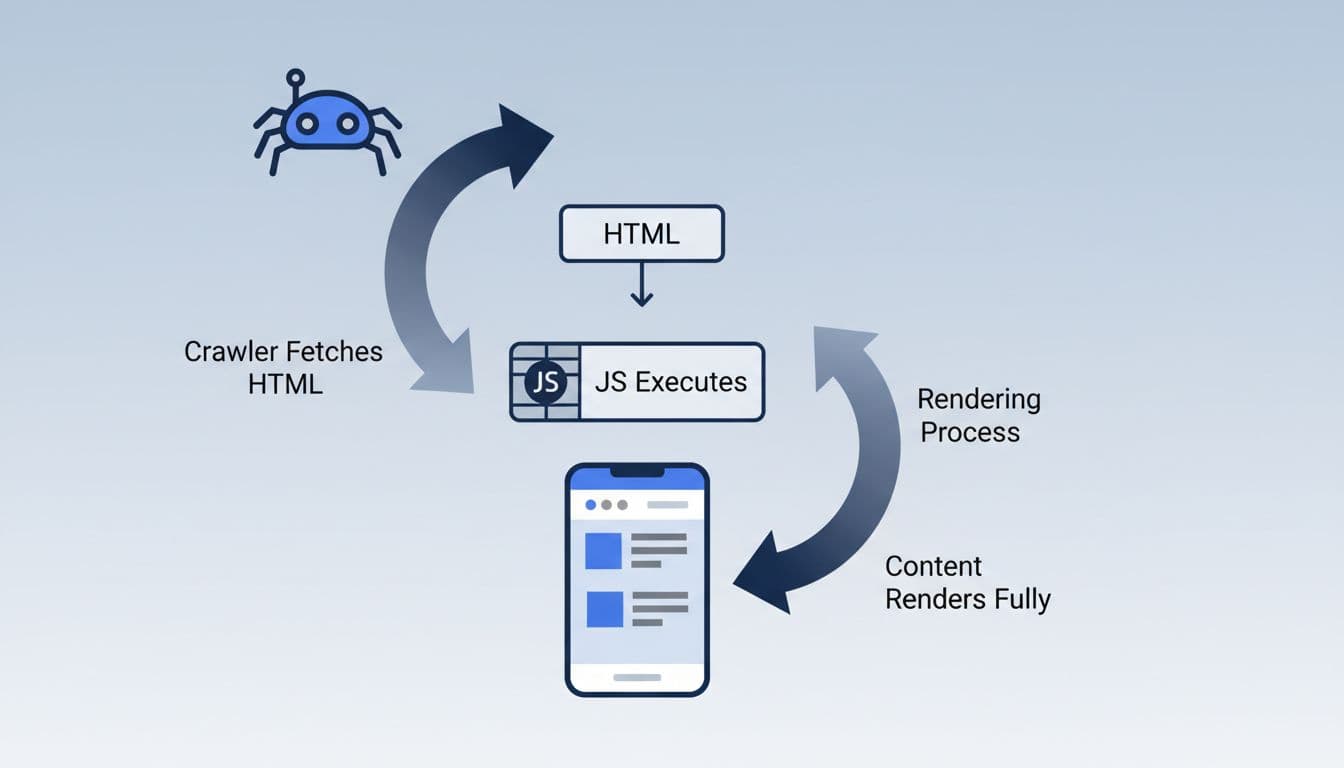
- İlk olarak response HTML’i inceleyin. “View Source” ya da sunucu yanıtı size sayfanın başlangıç durumunu gösterir. Burada H1, ana metin, ürün adı, breadcrumb, canonical, meta robots, meta description ve internal links var mı bakın.
- Sonra tarayıcıda rendered HTML’i açın. Elements paneli ya da benzer araçlar sonradan eklenen düğümleri gösterir. Kaynak HTML ile rendered HTML aynı değilse, farkın hangi öğelerde oluştuğunu not alın.
- Ardından Google görünümünü kontrol edin. Search Console’daki Canlı URL testi, Google’ın o anda neleri çekebildiğini görmek için yararlıdır. Ekran görüntüsü eksikse ya da HTML beklediğinizden farklıysa, sorun büyük ihtimalle gerçek bir render sorunudur.
- DevTools Network ve Console panellerini açın. Sayfa ancak belirli API çağrılarından sonra tamamlanıyorsa, o zincirdeki her hata indekslenebilir içeriği etkiler.
- Son olarak head bölümünü ayrı okuyun. Canonical tags, noindex, hreflang, structured data ve title, ilk yanıtta mı geliyor, yoksa JavaScript sonradan mı ekliyor? Bu ayrım çoğu zaman kök nedeni açığa çıkarır.
Aynı testte masaüstü ve mobil görünümü, giriş yapılmış ve yapılmamış durumu, ayrıca yönlendirme zincirini karıştırmayın. Tek URL varyantı üzerinde ilerlemek yanlış pozitifleri azaltır.
Ham HTML ile render edilmiş DOM’u karşılaştırma
İyi bir JavaScript SEO testi, initial HTML response ile rendering sonrası DOM’u karşılaştırarak “kaynakta ne var, son DOM’da ne var” sorusuna net yanıt verir. Burada aranan şey yalnızca içerik farkı değildir. Aynı zamanda SEO sinyallerinin hangi aşamada ortaya çıktığıdır.

Karşılaştırmada önce şu alanlara bakın: title, meta description, canonical, meta robots, H1, ana gövde metni, dahili linkler, resim src değerleri ve structured data. Bu öğelerden biri initial HTML response’ta yoksa ama son DOM’da görünüyorsa, sayfa istemci tarafına bağımlı demektir. Bu, her zaman hata değildir. Fakat bağımlılık ne kadar artarsa risk de o kadar artar. Bu bağımlılığı azaltmak için static site generation gibi yaklaşımlar kullanılabilir.
Pratikte işinizi hızlandıran araçlar var. JsBug karşılaştırması ham HTML ile headless Chromium çıktısını yan yana gösterir. SEO JS Checker eklentisi head etiketleri, metin ve link farklarını hızlıca listeler. Daha kısa rapor isteyenler için Rendering Difference Engine de işe yarar.
Burada problem sinyali sayılan bulgular nettir. Initial HTML response’ta yalnızca boş bir div varsa ve H1, paragraf metni, ürün kartları sonradan ekleniyorsa, bu sayfa bot için pahalı bir render süreci ister. Canonical kaynakta A iken render sonrası B’ye dönüyorsa, URL sinyali tutarsızdır. Meta robots initial HTML response’ta yok ama birkaç saniye sonra noindex oluyorsa, kontrol mekanizması güvenilmez hale gelir. Link sayısı initial HTML response’ta 5, render sonrası 80 oluyorsa, tarama keşfi büyük ölçüde JavaScript’e bırakılmış demektir.
Initial HTML response’ta olmayan kritik içerik, bot tarafından her ziyarette aynı kaliteyle görülmez. Bu yüzden başlık, ana metin ve temel linkler mümkünse initial HTML response’ta yer almalıdır.
Bir fark gördüğünüzde hemen “sorun bu” demeyin. Önce farkın ne kadar geç oluştuğunu ve oluşmak için hangi isteğe bağımlı olduğunu bulun. Asıl teşhis orada çıkar.
DevTools’ta ağ, konsol ve hydration mismatch
Render debugging çoğu zaman DevTools’un Network ve Console panellerinde çözülür. Çünkü eksik içerik genelde görünmeyen bir zincirin sonucudur: başarısız API çağrısı, geç dönen JSON, kırık bundle, hydration hatası ya da istemci yönlendirmesi.

Network panelinde önce AJAX çağrılarını (fetch ve xhr isteklerini) izleyin. Ana içerik bir API’den geliyorsa, durum koduna bakın. 401, 403, 404, 500, CORS hatası ya da timeout varsa, bot büyük ihtimalle eksik sayfa görecektir. Sayfa 200 dönüyor olabilir, ama veri isteği patladığı için gövdede “ürün bulunamadı” benzeri boş durum çıkabilir. Bu, soft 404 benzeri bir davranıştır.
Geç yüklenen başlıklar da burada görünür. İlk 1 saniyede yalnızca iskelet ekran var, H1 ise üçüncü saniyede API cevabından sonra geliyorsa, sayfanın en önemli metni istemci tarafına fazla bağımlıdır. Lighthouse bu noktada yükleme zincirini ve render-blocking kaynakları görmek için hâlâ yararlıdır. Büyük JS paketleri, uzun ana iş parçacığı süresi ve geç çalışan hydration, Core Web Vitals metriklerini bozarak SEO sorununun performans tarafını da gösterir.
Console paneli ayrı bir hazine. JS konsol hataları burada belirir; “hydration mismatch” uyarıları, sunucudan gelen HTML ile istemcinin ilk render’ı arasında fark olduğunu söyler. React, Vue ya da benzer yapıların bu uyarıları, metin düğümlerinin değiştiğini, liste sıralarının farklılaştığını veya istemci tarafında farklı veri üretildiğini gösterir. Tarih, kur, rastgele sıralama, kullanıcıya özel metin ve koşullu bileşenler sık nedenlerdir.
Bu uyarıları küçümsemeyin. Çünkü hydration bozulduğunda başlık, breadcrumb, ürün sayısı, fiyat ya da açıklama kısa süreliğine değişebilir. Arama motorunun gördüğü belge ile kullanıcının sonradan gördüğü belge ayrışır. O anda sorun yalnızca UX değildir, indeksleme sinyali de kirlenir.
Robots engelleri ve geç eklenen head sinyalleri
Bazı render sorunları JavaScript’in kendisinden değil, ona giden yolun kesilmesinden doğar. En klasik örnek robots.txt dosyası ile engellenen JS veya CSS dosyalarıdır. Sayfa HTML olarak açılır, ama ana uygulama paketi ya da stil dosyası yüklenemez. Sonuçta metin alanı boş kalır, sekmeler çalışmaz ya da içerik gizli sınıfta takılı kalır.
Bunu tespit etmek için yalnızca sayfa kaynağına bakmayın. Kaynağın çağırdığı bundle dosyalarının gerçekten indirilebildiğini doğrulayın, özellikle robots.txt tarafından engellenip engellenmediğini kontrol edin. Search Console canlı testinde bozuk ekran görüntüsü, eksik stil veya görünmeyen bileşenler görürseniz kaynak erişimini inceleyin. İndeks tarafındaki sonuçları okumak için Canlı URL testi ile indeksleme sorunları rehberi da yardımcı olur.
İkinci kritik alan head bölümüdür. Canonical tags ve noindex bazen route değişiminde, bazen de tag manager ile sonradan eklenir. Bu client-side yaklaşım sık hata üretir ve indexing süreçlerini bozar. Kaynak HTML’de canonical tags yoksa, render sonrası eklenmiş olsa bile sinyal geç kalmış olabilir; bu technical SEO açısından büyük risk taşır. Daha kötüsü, kaynakta index olan sayfa istemci tarafında noindex olur ya da tersi yaşanır. Bu durumda botun gördüğü durumla beklediğiniz durum aynı kalmaz.
Canonical tags ve noindex, sonradan serpiştirilecek etiketler değildir. İlk yanıtla uyumlu olmalı ve route değişimlerinde çakışmamalıdır.
Burada çözüm basittir. Head sinyallerini mümkün olduğunca sunucu tarafında üretin. Framework kullanıyorsanız server-side rendering ile metadata stabilitesini sağlayın, SSG ya da en azından kritik şablonlar için önceden render edilmiş head çıktısı verin. Tag manager, analytics ya da kişiselleştirme katmanı yüzünden canonical tags ve robots değiştirme; server-side rendering bu tür client-side sorunlarını önler ve technical SEO’yu güçlendirir.
Lazy-load ve render sonrası oluşan linkler
Lazy-load doğru yerde kullanılırsa faydalıdır, ama yanlış yerde crawling verimliliğini düşürerek görünmez içerik üretir. Sorun genelde resimlerde başlar, sonra metin bloklarına ve ürün listelerine kadar uzanır. Üst bölümdeki görselin gerçek src değeri yoksa, yalnızca data-src varsa ve istek ancak scroll sonrası gidiyorsa, bot bu görseli kaçırabilir. Aynı mantık metin için de geçerlidir. İçerik Intersection Observer tetiklenmeden gelmiyorsa, görünürlük garanti değildir.
Bunu anlamanın yolu basittir. Sayfayı açın, hiç etkileşim yapmadan DOM’u ve Network panelini izleyin. Üst bölüm içeriği için resim isteği çıkmıyorsa, placeholder HTML kalıyorsa ya da kartlar ancak kaydırınca oluşuyorsa sorun bellidir. Görsel tarafında Crawlably render kontrolleri ve daha geniş DOM analizi için SEOries JavaScript SEO Analyzer faydalı olabilir.
Dahili linkler de benzer şekilde kaybolur. Single-page apps menü linkleri yalnızca hamburger tıklanınca oluşuyorsa, kategori kartları API sonrası a etiketi kazanıyorsa ya da pagination butonları buton olarak kalıp gerçek URL üretmiyorsa, crawlable links tarama keşfi zayıflar. Kullanıcı tıklayarak bir yere gider, ama bot o yolu yeterince erken görmez.
Kalıcı çözüm, kritik öğeleri ilk render’a taşımaktır. Önemli görseller için gerçek src ve srcset verin. Ana navigasyon ve internal links’leri HTML içinde üretin; History API kullanarak internal links navigasyonunu doğru yapın. Sayfa içeriği yalnızca istemci verisine bağlıysa, SSR, SSG, ISR ya da kritik rota bazlı prerender düşünün. Dynamic rendering ise 2026’da hâlâ kısa süreli bir köprü olabilir, fakat uzun vadeli mimari çözüm yerine geçmez.
Sorunları hızlı okumak için teşhis tablosu
Aşağıdaki tablo, sahada en çok görülen render sorunlarını kısa yoldan sınıflandırır.
| Sorun | Nasıl tespit edilir | Olası çözüm |
|---|---|---|
| Boş veya eksik render edilen içerik | Kaynak HTML’de gövde boş kalır, son DOM içerik ekler, canlı test ekranı eksik görünür | Ana içerik bloklarını server-side rendering (SSR) veya static site generation (SSG) ile ilk yanıta taşıyın |
| Geç yüklenen başlık ve metinler | H1 ve giriş metni yalnızca API çağrısından sonra görünür | Başlık, özet metin ve breadcrumb’ı ilk HTML’de verin |
| robots.txt ile engellenen JS veya CSS | Bundle ya da stil dosyası robots.txt/403 yüzünden yüklenmez, görünüm bozulur | Kritik JS ve CSS dosyalarını indexing için taramaya açın, yolu sadeleştirin |
| Canonical tags veya noindex’in JS ile sonradan eklenmesi | Kaynak head ile render sonrası head farklıdır | Canonical tags ve robots etiketlerini sunucu tarafında üretin |
| Lazy-load yüzünden görünmeyen görseller | src boş kalır, istek ancak scroll sonrası gider | Üst bölüm görsellerinde lazy-load’u kaldırın, gerçek kaynak verin |
| Lazy-load yüzünden görünmeyen içerik | Metin veya ürün kartı gözleme dayalı tetikleyici olmadan gelmez | Ana gövdeyi görünür HTML olarak gönderin, etkileşim bağımlılığını azaltın |
| Dahili linklerin (internal links) render sonrası oluşması | Kaynak HTML’de link yoktur, sonradan a etiketi eklenir | Navigasyon, kategori ve pagination linklerini ilk HTML’de üretin |
| Hata veren API çağrıları | XHR/fetch isteklerinde 4xx, 5xx, timeout, CORS veya JS console errors görülür | API hatalarında boş sayfa döndürmeyin, cache ve fallback ekleyin |
| Hydration mismatch | Console uyarıları çıkar, sunucu ve istemci içeriği ayrışır | Sunucu ve istemci verisini eşitleyin, rastgele ve kullanıcıya özel çıktıları ayırın |
| Soft 404 benzeri durumlar | Sayfa 200 döner, fakat render sonrası “bulunamadı” veya boş durum gösterir | Gerçek 404/410 kullanın, boş kategoriye açıklayıcı içerik ve doğru durum kodu verin |
Tablonun özeti basit: tek bir belirtiye bakıp karar vermeyin. En net teşhis, HTML farkı, ağ hatası ve head etiket kontrolü birlikte okunduğunda çıkar. Eğer üçü aynı yere işaret ediyorsa, sorun neredeyse her zaman gerçek bir render problemidir.
Sıkça Sorulan Sorular
JavaScript SEO testi neden önemlidir?
JavaScript sitelerinde Googlebot sıklıkla boş kabuk görürken kullanıcı tam sayfayı görür; bu fark indeksleme kalitesini düşürür. Test, initial HTML ile rendered DOM arasındaki tutarsızlıkları yakalayarak teknik SEO’yu güçlendirir. Kritik içerik client-side’a bırakılırsa gecikme ve tutarsızlıklar oluşur.
Render sorunu nasıl tespit edilir?
İlk HTML response’u (View Source) rendered Elements ile karşılaştırın, head etiketleri ve link farklarını not alın. DevTools Network’te API hataları (4xx/5xx, timeout), Console’da hydration mismatch uyarılarını kontrol edin. GSC Canlı URL Testi ile bot’un gerçek görüntüsünü doğrulayın.
Canonical ve noindex etiketleri neden initial HTML’de olmalı?
Client-side eklenen sinyaller geç kalır veya tutarsızlaşır, bot indeksleme sırasında farklı sonuçlar görür. Sunucu tarafında üretilmezse risk artar, duplicate content veya istenmeyen indeksleme sorunları çıkar. SSR veya SSG ile head stabilitesini sağlayın.
Hydration mismatch nedir ve etkisi nedir?
Sunucu HTML’i ile client render’ı arasındaki farkı gösterir; React/Vue gibi framework’lerde tarih, sıralama veya kişiselleştirme neden olur. SEO’da başlık, metin veya linkler değişirse indeks sinyali kirlenir. Sunucu-istemci verisini eşitlemek çözüm getirir.
Lazy-load SEO’yu nasıl etkiler?
Üst kısım görselleri veya içerikler scroll beklerse bot kaçırabilir, crawlable olmaz. Dahili linkler render sonrası oluşursa tarama keşfi zayıflar. Ana öğeleri ilk HTML’e taşıyın, lazy’i alt kısımlarda sınırlayın.
Sonuç
Bir sayfa normal görünse bile Googlebot için eksik olabilir. Bu yüzden JavaScript SEO testi, teknik SEO’nun temel bir sütunu olarak görsel kontrolden ibaret kalmaz; ham HTML, render edilmiş DOM, Network, Console ve head etiketleri birlikte okunur. Rendering süreci sürekli izlenmelidir.
En güçlü kural şudur: kritik içerik ve kritik sinyaller ilk yanıtta yer almalıdır. Başlık, ana metin, dahili linkler, canonical ve robots sonradan geliyorsa risk artar.
Bugün tek bir önemli şablonu seçip kaynak HTML ile son DOM’u yan yana koyun. Çoğu büyük sorun, o ilk karşılaştırmada kendini zaten belli eder.
